Motivation
“Extrapolation”의 정의
•
Language model을 학습할 때 사용하는 문장(서열)의 최대 길이를 이라 하자.
•
Transformer 이전, RNN 으로 구현된 language model들은 짧은 에서 학습되고, 학습된 모델이 inference 시에 긴 로 잘 일반화할 것이라고 가정했다.
•
Transformer 구조를 제시한 “Attention is all you need” 논문에서도 마찬가지로, 학습 시보다 inference 시에 이 길어도 잘 일반화될 것이라고 가정했다.
•
이러한 맥락에서, 아래와 같이 “Extrapolation”을 정의하고, 논문에서 주요 개념으로 활용한다.

Extrapolation
•
학습시에 사용한 서열의 길이 보다 긴 서열에 대해서 얼마나 모델 성능이 유지되는지를 나타내는 개념.
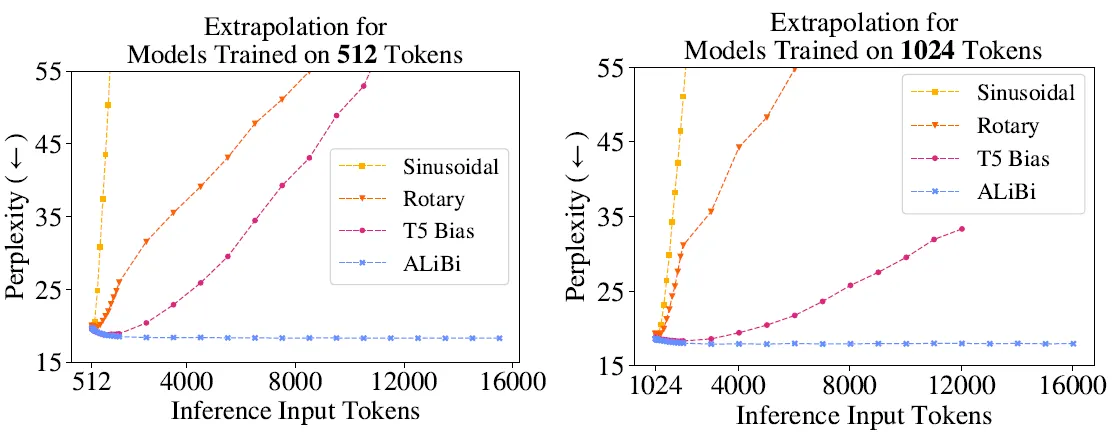
•
Sinusoidal position encoding을 사용하는 transformer는 extrapolation 능력이 좋지 않다!
•
Rotary position encoding, T5 Bias 등의 방법들을 사용하면 extrapolation 능력이 좋아지지만, 그마저도 충분하지는 않다.
Attention with Linear Biases (ALiBi)

ALiBi의 head-specific slope를 정하는 방법
•
ALiBi 구현에 있어서 고려해야 할 사항은 head-specific slope 뿐이다. 어떻게 값을 설정했는지를 알아보자.
•
논문의 transformer에서는 8개의 head를 사용한다. 이 때, 각 head의 slope는 아래와 같은 등비급수로 설정한다.
•
만약 16개의 head를 사용하는 모델이 있다면, 아래와 같이 설정하면 된다고 제안하고 있다.
•
그러면 일반적으로 n개의 head가 있는 경우에는?
•
를 초항으로 하고, 역시 을 공비로 하는 등비급수를 slope로 사용하면 된다!