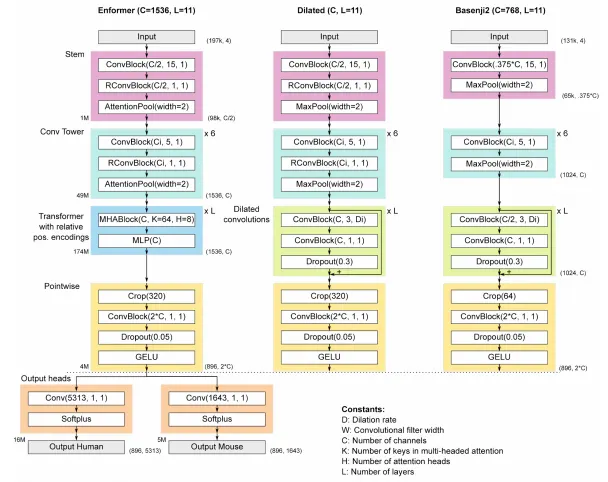
모델 구조
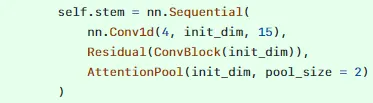
프로젝트 Scaffold 만들기
첫 class 구현
AttentionPool 구현
class AttentionPool(nn.Module):
def __init__(self, dim, pool_size = 2):
super().__init__()
# b=batch size, d=channel, n=L/2, p=2
self.pool_fn = Rearrange('b d (n p) -> b d n p', p = 2)
self.to_attn_logits = nn.Parameter(torch.eye(dim))
def forward(self, x):
attn_logits = einsum('b d n, d e -> b e n', x, self.to_attn_logits)
x = self.pool_fn(x)
attn = self.pool_fn(attn_logits).softmax(dim = -1)
return (x * attn).sum(dim = -1)
Python
복사

•
einsum 작동 방식?
◦
최종적으로는 AttentionPool이 이렇게 구현된다
class AttentionPool(nn.Module):
def __init__(self, dim, pool_size = 2):
super().__init__()
self.pool_size = pool_size
self.pool_fn = Rearrange('b d (n p) -> b d n p', p = pool_size)
self.to_attn_logits = nn.Conv2d(dim, dim, 1, bias = False)
# in_channels=dim, out_channels=dim, kernel_size=1, stride=1, bias=False
# dim -> dim으로 가는 변환. dim=C 라고 보면 된다.
# Conv2d weight initialize가 identity matrix로 되던가?
def forward(self, x):
b, _, n = x.shape
remainder = n % self.pool_size
needs_padding = remainder > 0
if needs_padding:
x = F.pad(x, (0, remainder), value = 0)
mask = torch.zeros((b, 1, n), dtype = torch.bool, device = x.device)
mask = F.pad(mask, (0, remainder), value = True)
x = self.pool_fn(x)
logits = self.to_attn_logits(x)
if needs_padding:
mask_value = -torch.finfo(logits.dtype).max
logits = logits.masked_fill(self.pool_fn(mask), mask_value)
attn = logits.softmax(dim = -1)
return (x * attn).sum(dim = -1)
Python
복사
•

Residual class 구현
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(x, **kwargs) + x
Python
복사
•
이렇게 Residual operation을 따로 클래스로 구현해 두면 nn.Sequential 내에서 이렇게 편리하게 사용 가능하다.